LTSPICE files available here: github.com/KevinNJ.
Overview
Recently, a friend of mine has been working on a circuit for maximum power point tracking (mppt) of his solar panel array. The circuit he’s chosen is a Weinberg DC-DC isolating buck converter, chosen for it’s very high potential efficiency. The circuit looks pretty simple in principal, but when he built a prototype of the circuit we were seeing some effects that I didn’t understand. I decided to simulate the circuit in SPICE, and post the results of the analysis here.
Circuit
First, let’s take a look at the schematic.
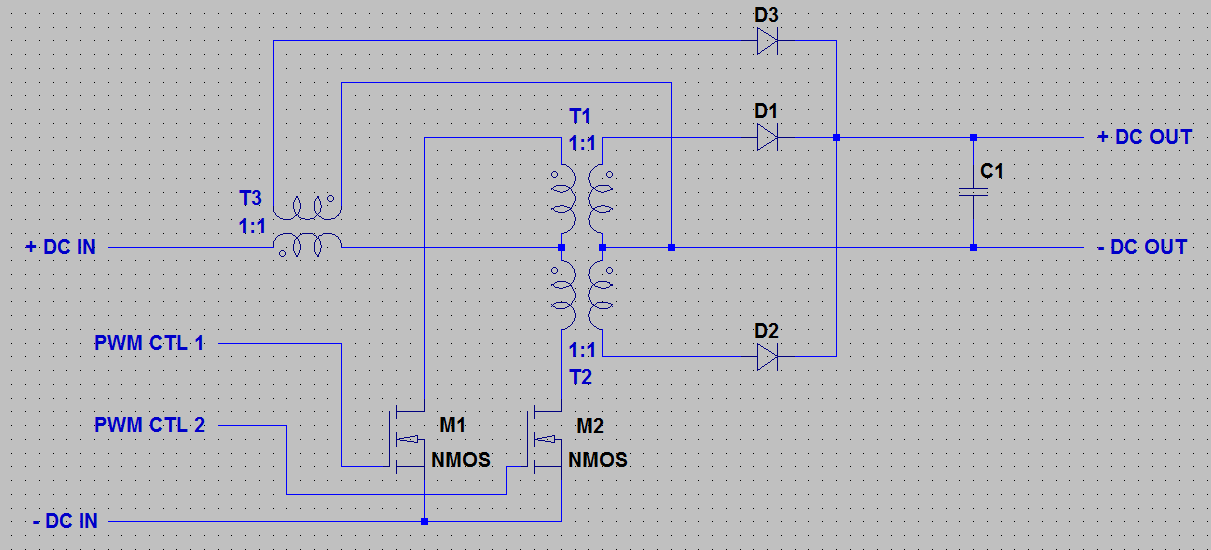
Weinberg Buck Converter
There aren’t any values chosen for this circuit, although like a lot of power circuits, I don’t think that the values of the majority of components are particularly critical – as long as all parts can handle expected voltages and currents. Here are things to watch out for when picking parts:
- None of the transformers should not saturate when storing energy. This has to do with the transformer core material, inductance of the primary (number of windings on the core), and switching frequency.
- Fast diodes (low voltage drop) are critical for efficiency
- Low series resistance on the inductors and ESR on the capacitors is also important for efficiency
Looking at this circuit, it’s pretty clear how it’s supposed to work. M1 and M2 are switched on and off 180 out of phase with one another. The duty cycle of the switching signal controls the output bus voltage.
This configuration looks a lot like two flyback converters (wikipedia) in parallel. The wikipedia article above has a good description of how this circuit works, but I’ll copy a little bit of info here for reference.
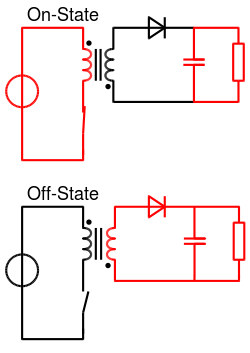
Two operating states of a flyback converter (wikipedia)
When the switch is turned on, current is drawn through the transformer, increasing the magnetic flux of the transformer core. The voltage across the secondary is negative, reverse biasing the diode. Energy is stored in the transformer in the form of magnetic flux. During this half of the cycle, the load is powered from the capacitor.
When the switch is turned off, the voltage in the secondary turns positive forward biasing the diode. The stored energy in the transformer is released through the secondary to charge the capacitor and power the load.
It looks like when either M1 or M2 are on and charging T1 or T2, a voltage is also induced across T3 charging it. We would guess then that T3 would only discharge when both M1 and M2 are off.
Below is a table of the different states that M1 and M2 can be in against the different states that each transformer will be in.
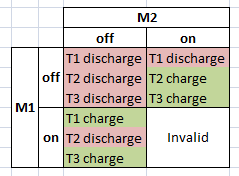
N-FET conduction vs Transformer State
And a waveform showing 1 PWM cycle of M1 and M2 against the transformer states.
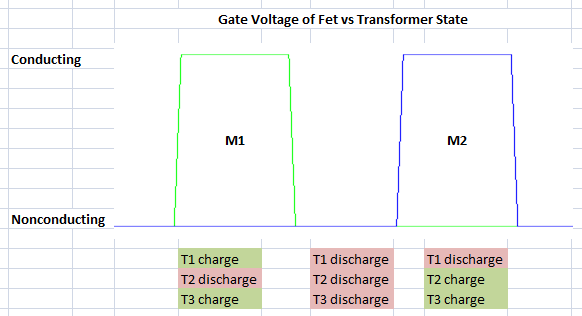
N-FET Gate Voltage vs Transformer State
Circuit Simulation and Analysis
Alright, let’s set up SPICE to handle our circuit particulars. I’m using the following circuit:

Weinberg SPICE Model
A few quick notes about transformers in LTSPICE:
- K statements are used to make transformers from 2 inductor elements. What will be referred to in this article as transformer T1 is marked in the SPICE schematic as K1. T2 and T3 are marked likewise.
- In SPICE there is no such thing as a turns ratio. The model only knows about the ratio of the inductance of each side. To calculate the necessary inductance ratio to achive a proper turns ratio, it is helpful to remember that inductance is proportional to the square of the number of turns.
- Note that in the simulation both the primary and secondary need to be referenced to the same ground. This guarantees that the circuit has appropriate boundary conditions and we don’t get convergence errors. This does not need to be the case in real life.
- See Using Transformers in LTSPICE for more information.
First off, let’s look at what happens to the voltage and current on the output bus using the transient simulation. I’ve set an end time of 15 ms which runs reasonably fast on the computer and allows the circuit to reach steady state. The PWM inputs are set to a 25% duty cycle.
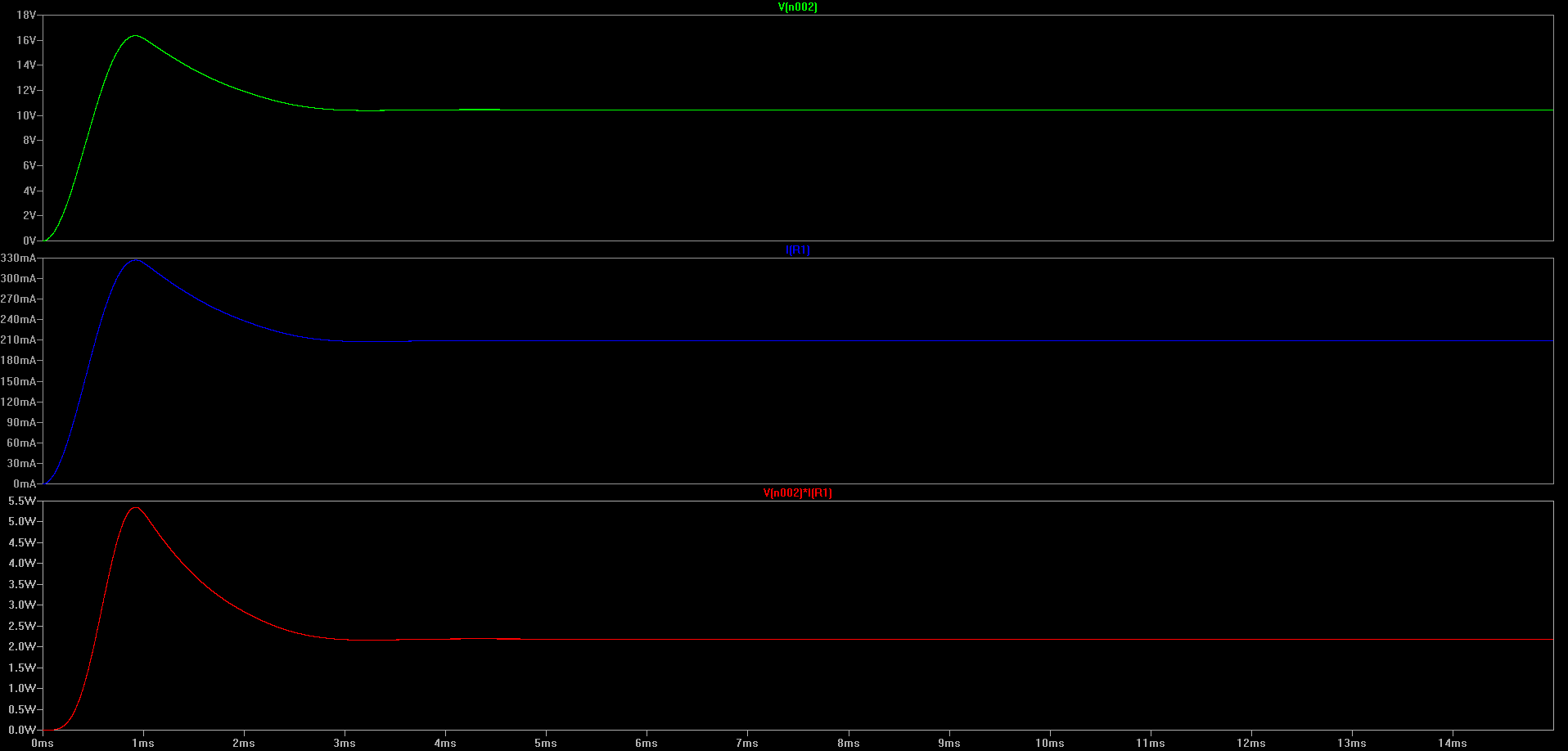
Voltage across load, current through load, and power sinked by load
(Click for higher resolution version)
So it looks like our circuit might be simulating correctly. We appear to be generating a voltage across the load which is about 1/4 of the input voltage. There is a transient in the first 3 ms or so which then dies out and the circuit reaches a steady state value.
Let’s see if charging and discharing of the transformers works like we think it does. Below is the power flowing through the primary and secondary of T1.
Top: Voltage applied to N-FET gate (high => FET is conducting)
Middle: Power being sinked by T1 (K1) primary from Source
Bottom: Power being sourced by T1 (K1) secondary to Load
(Click for higher resolution version)
It looks like the system sort of works like how we guessed. When the N-FET is on, power is stored in the T1 transformer. When the fet is turned off, that power is sourced into the load through the secondary. There are some ripples which haven’t been explained yet, but we can safely ignore those for now.
T2 acts identically to T1, but 180 degrees out of phase. I’m not going to display the graphs here though to save space.
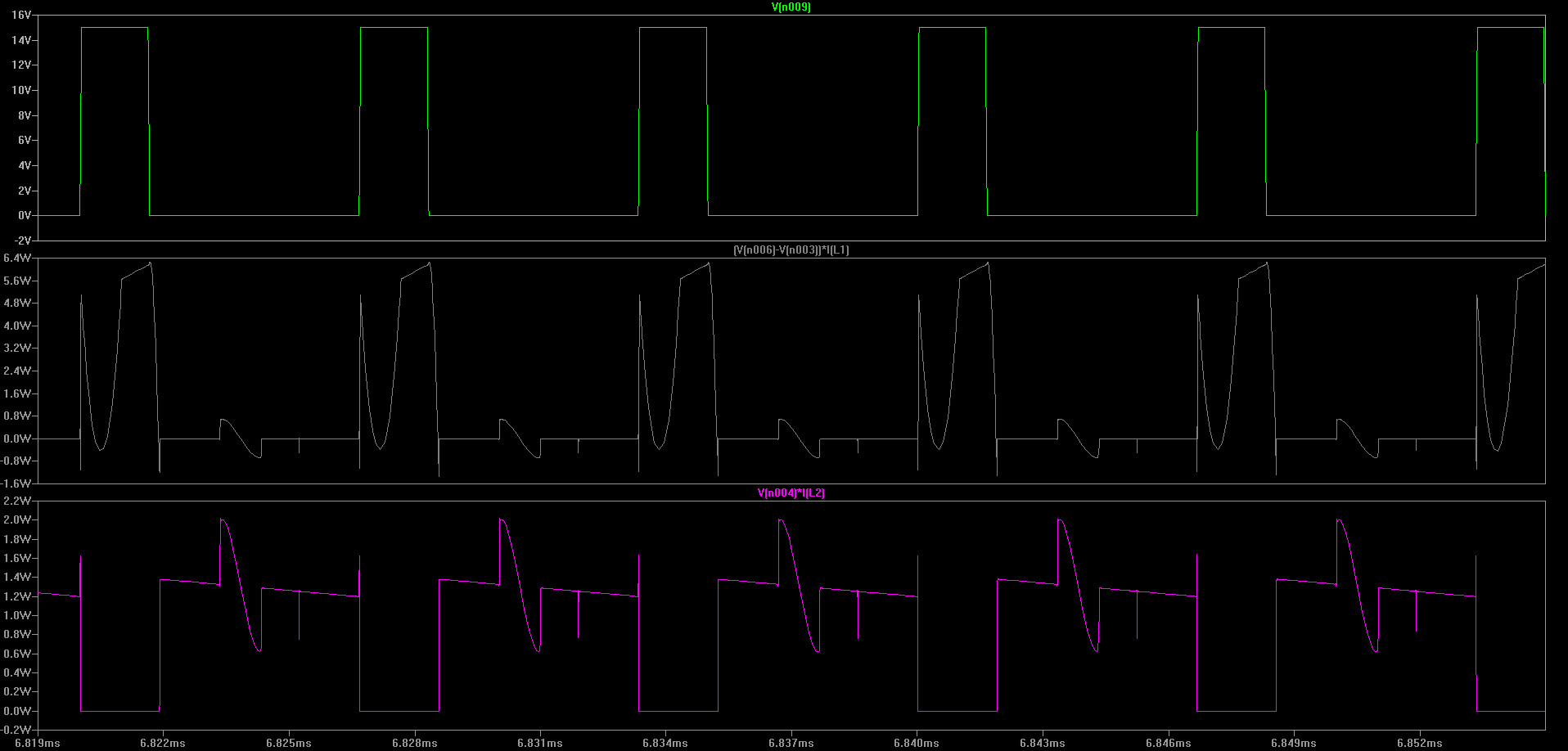
Let’s check out how the power transfer in T3 works.
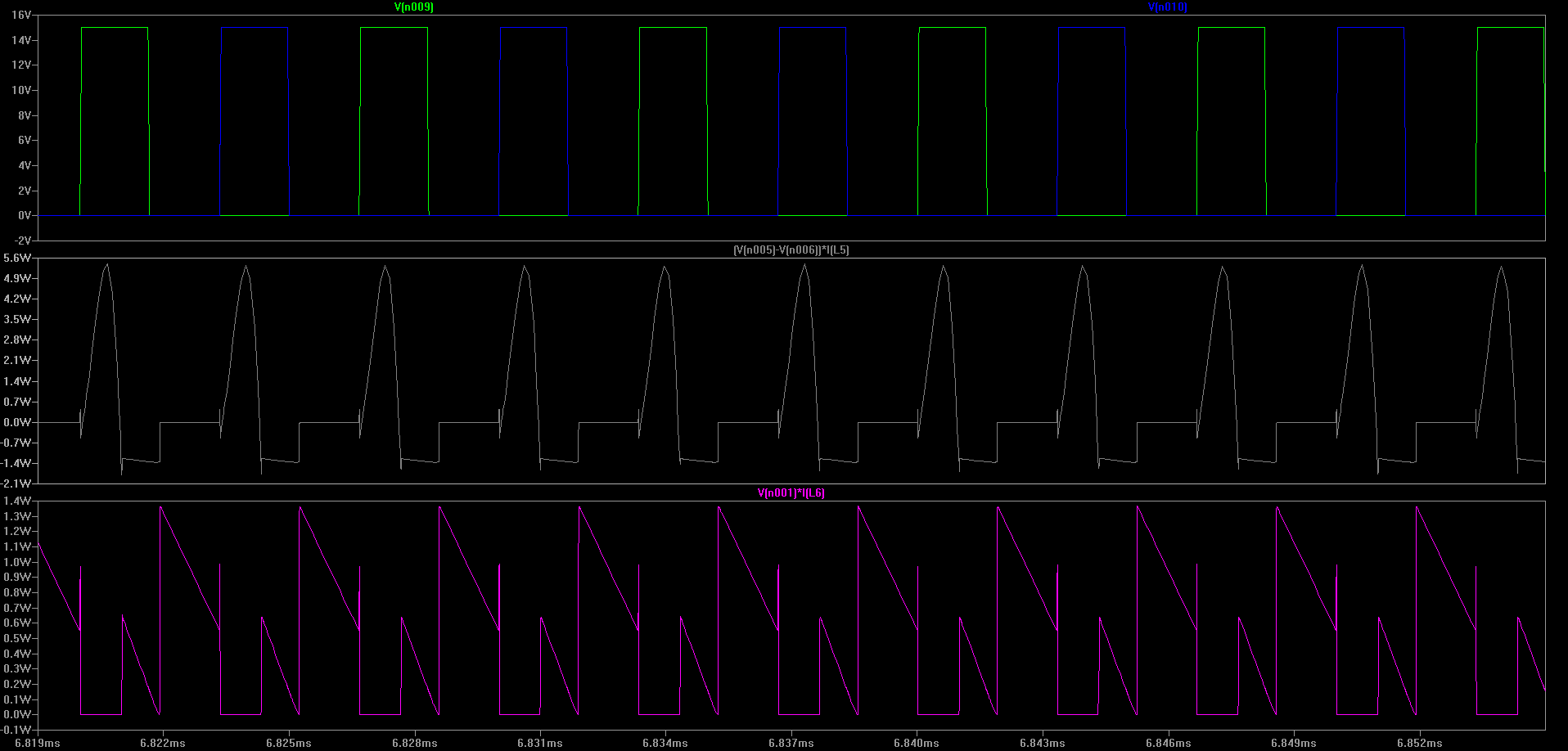
Top: Gate voltages applied to M1 (green) and M2 (blue)
Middle: Power sinked by primary of T3 (K3) from Source
Bottom: Power sourced by secondary of T3 (K3) to Load
(Click for higher resolution version)
So, every time a FET is turned on, T3 charges. Any time that both FETs are off T3 is discharging. So this transformer works a lot like how we guessed it would.
Unfortunately it’s a little difficult to measure power in a real circuit, so here’s a graph of the expected voltages at various places in the circuit. This should give us expected values to look for when probing the circuit with an oscilloscope.
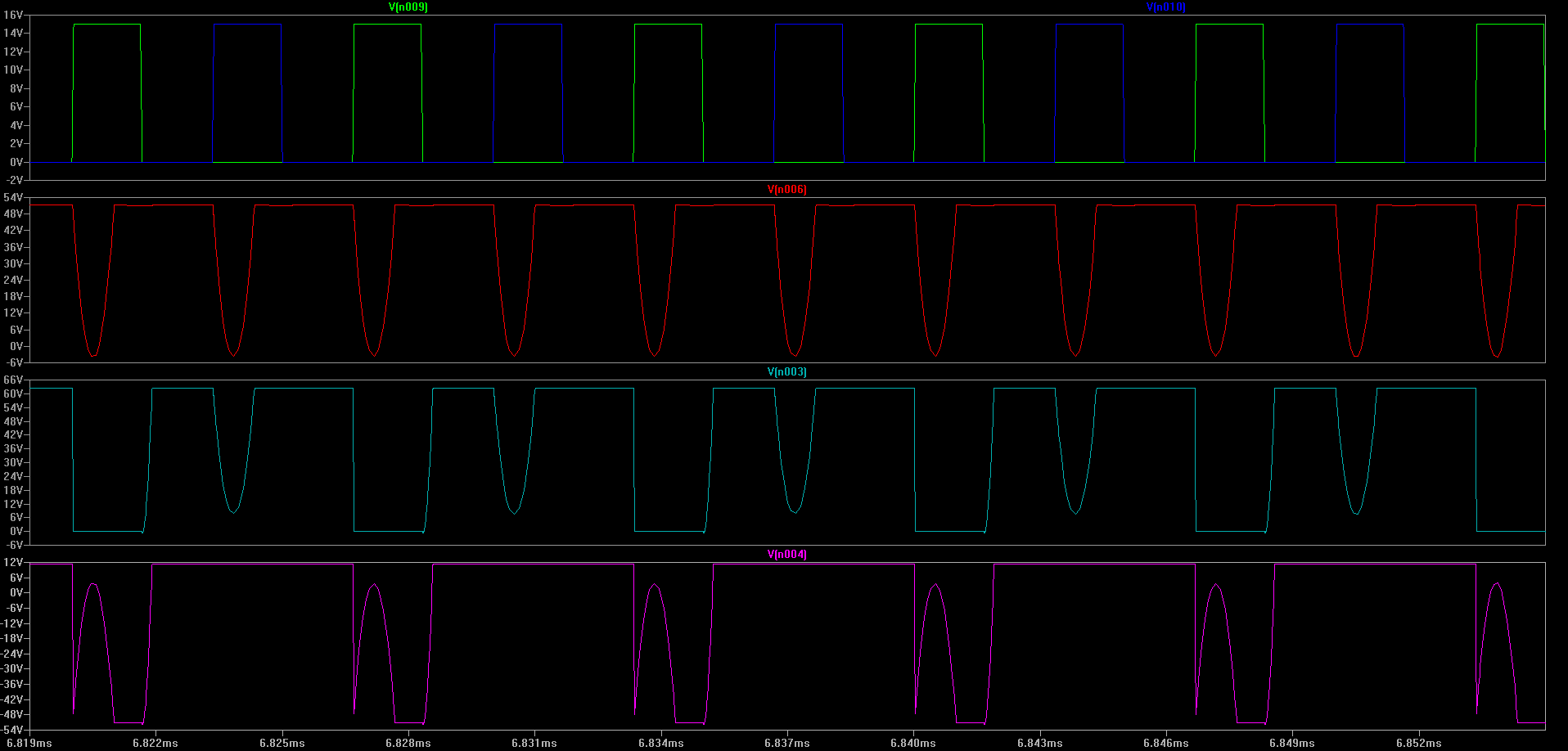
First: Voltage being applied to gates of M1 (green) and M2 (blue)
Second: Voltage between primary of T3 and T1/T2
Third: Voltage between primary of T1 and M1 N-FET
Last: Voltage between secondary of T1 and D1
(Click for higher resolution version)
After prototyping one of these circuits, it’s apparent that the actual waveforms are much less nice than these. There are all sorts of voltage spikes and ringing which this simulation does not show. This is most likely because we are simulating ideal inductors (coupling coefficient of 1). It’s actually handy to do so for now because it gives us a good general picture of how we should expect the timing of events in our circuit to behave.
Leakage Inductance
The biggest problem for us in this circuit is the leakage inductance on our transformers. Leakage inductance is caused when magnetic flux in one of the wingdings does not pass through the other winding. It’s sort of like having an extra inductor on the end of the transformer.
Having leakage inductance causes major problems in a flyback circuit. I don’t have a good reference which completly describe the effects of leakage inductance, but it appears that it causes the following effects in a flyback circuit:
- Significantly increased voltage transients on the MOSFETs
- High Frequency Ringing
Some references online talked about how leakage inductance affects the power transfer between the primary and the secondary. Basically it traps some of the power in the primary causing the ringing and transients. At first glance this seems sort of reasonable – the leakage inductance would certainly store some energy and it wouldn’t be possible for that energy to cross to the secondary. However, I haven’t played with the circuit in SPICE enough to fully understand this effect.
Because of this, in a standard flyback circuit design, it is imperative to use tightly coupled transformers. My guess is that torroidal or E-core transformers are the best choice – a transformer should be used where the entire flux path is made of a magnetically conductive material.
Simulating a Non-Ideal Circuit
In SPICE we can simulate the leakage inductance in our transformers. I don’t have a good feel for the actual coupling coefficient in the real circuit we prototyped, but choosing a nice round 90% produces a more realistic simulation.
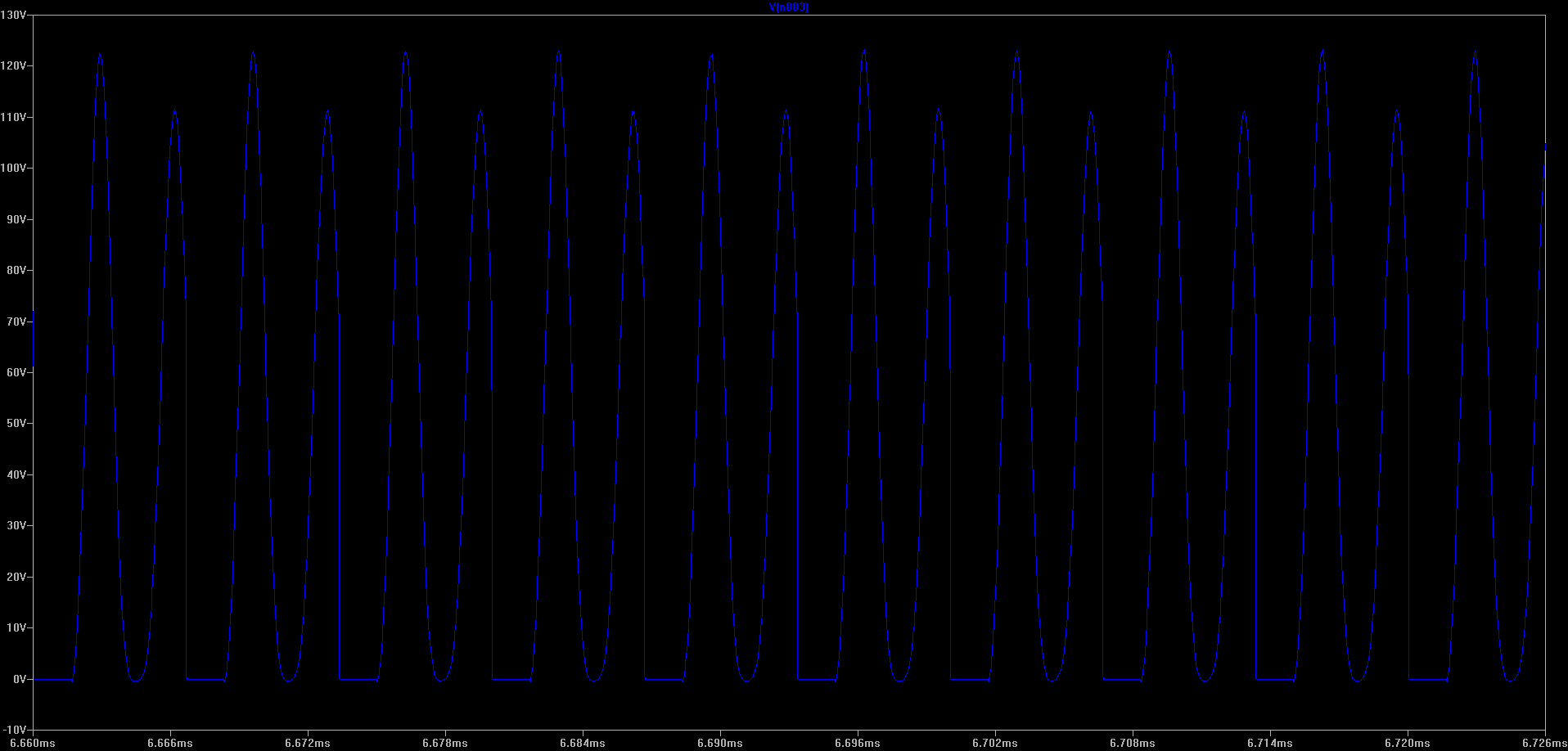
Voltage across M1 N-FET when leakage inductance has been changed to 0.9
(Click for higher resolution version)
The voltage across the N-FET basically doubled in the circuit. This means that in the current circuit, the FETs we choose would require a very high breakdown voltage.
In the prototyped circuit we were able to push the voltage transients up past 300V before our FETs started smoking. As it’s hard to source FETs with this kind of breakdown voltage (cheaply), some modification to the solution is required.
Snubbing the Transient Voltages
There is an interesting solution to this problem which I found when doing some background reading on flyback circuits. The topology is called a single-ended primary inductor converter or SEPIC.
There are many different slight variations on this topology but the basic modification is to couple the primary and secondary of the inductors through a capacitor. This helps clamp the transient voltages and remove the ringing from the circuit.
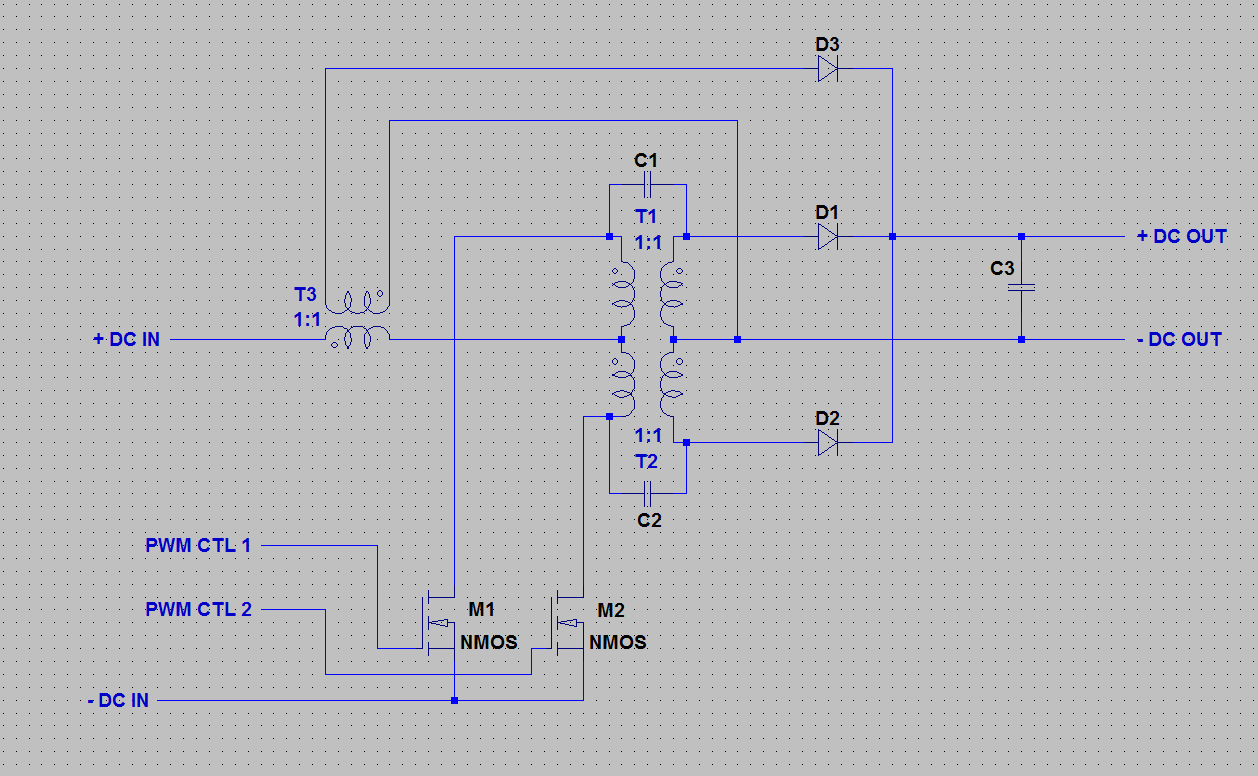
SEPIC circuit (flyback with coupling capacitors added)
Upsides of this circuit are much lower break down voltage requirements on the FETs. This circuit is also supposed to act like a (non-inverting) buck-boost topology, although I haven’t tried simulating a condition where it boosts the voltage yet.
Downsides to this topology is the fact that the topology is 4th order making it more difficult to control. However, I don’t think that this will be an issue in the intended use case.
Simulation of SEPIC Modifications
Setting the new capacitors to the values given below seemed to produce reasonable results.
- C1: 1 uF
- C2: 1 uF
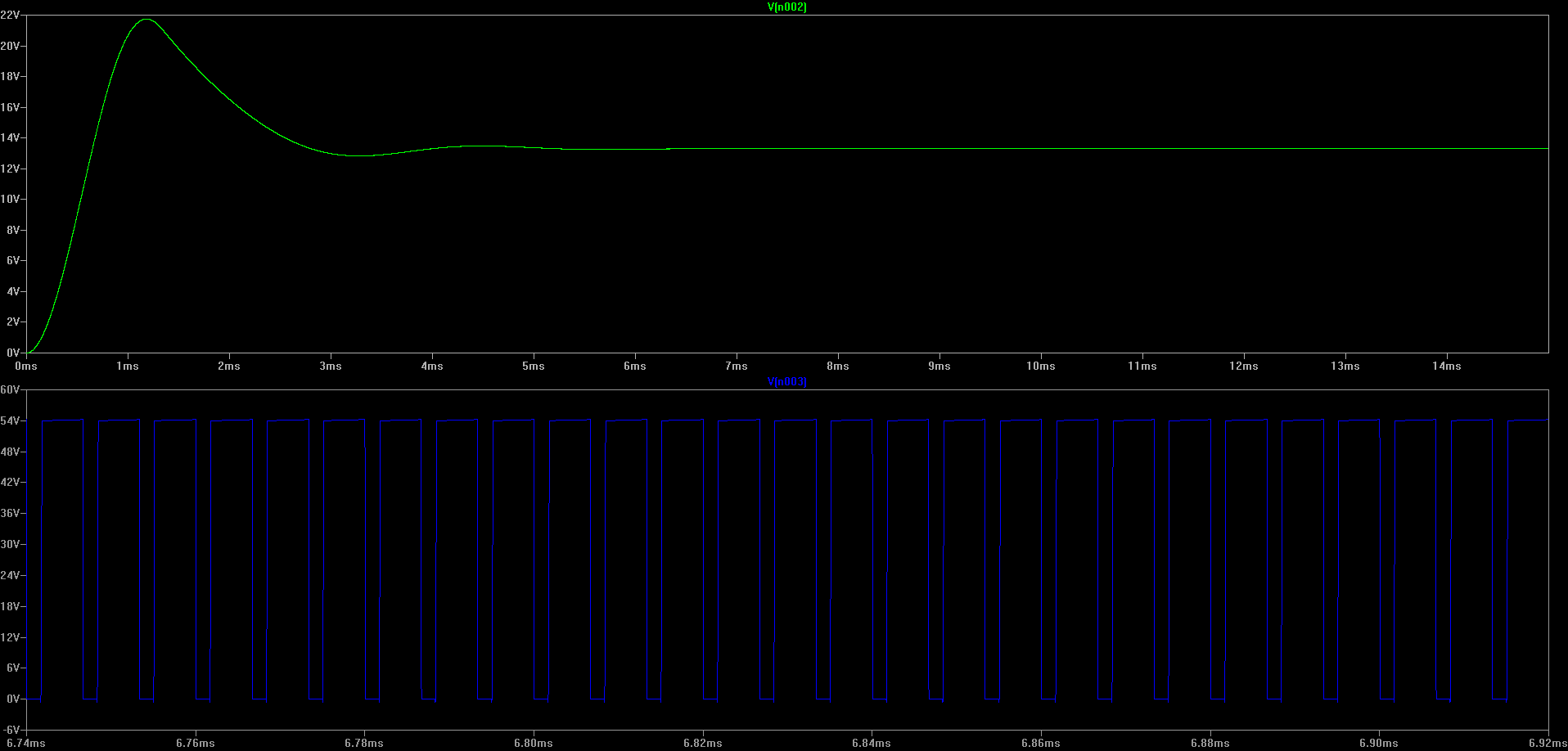
Top: Voltage on output bus
Bottom: Voltage across M1 N-FET
Note: Plots not to same time scale. (Click for higher resolution version)
From the extra ringing in the output bus, it’s evident that we’ve increased the order of the circuit.
However, when we look at the voltages across the N-FETs, the results look way more reasonable. We’ve brought the voltage values back down basically the values on the ideal circuit! Also, the ringing we were seeing seems to completely have disappeared.
Related Reading


 (maximally flat response, or no resonance peak)
(maximally flat response, or no resonance peak)